
· Juan Morisetti · Técnica · 17 min read
RAG en Spring AI
Cómo hacer que una IA realmente entienda tu aplicación
Una introducción práctica a Retrieval-Augmented Generation (RAG), embeddings y búsqueda semántica en aplicaciones Java con Spring Boot
En el último tiempo, los modelos de lenguaje empezaron a aparecer por todos lados. Chatbots, asistentes, generación de contenido, búsqueda inteligente, automatización… eventualmente terminás probando alguno y entendiendo por qué generaron tanto ruido.
En general, después de las primeras pruebas, suele aparecer la misma idea: “Esto dentro de una aplicación real tendría muchísimo potencial”. Sí, es cierto, aunque problema empieza cuando intentamos llevar esa experiencia a un sistema propio. Porque del dicho al hecho…
Los modelos son muy buenos entendiendo lenguaje, redactando respuestas y encontrando patrones, motivos suficientes para sernos de ayuda en consultas del día a día, pero no conocen absolutamente nada sobre nuestro negocio, y si lo que necesitamos es algo muy específico, quizá estemos en problemas.
Claro, no saben:
- qué información tenemos en nuestra base de datos
- cómo funciona nuestro sistema
- qué documentación interna manejamos
- ni qué pasó hace diez minutos en producción
Y ese probablemente sea uno de los mayores límites de cualquier LLM cuando sale del terreno de las demos.
El problema del conocimiento estático
Cuando usamos herramientas como ChatGPT, muchas veces da la sensación de que el modelo “sabe todo”. Pero en realidad, trabaja sobre información aprendida durante su entrenamiento. Por ende, implica varias limitaciones importantes.
Por ejemplo:
- tiene una fecha de corte de conocimiento
- no conoce información privada
- no accede automáticamente a nuestros sistemas
- no tiene contexto sobre datos internos o eventos recientes
Un modelo puede explicarte perfectamente qué es PostgreSQL o cómo funciona Spring Boot, pero no tiene idea de:
- qué clientes tiene tu empresa
- qué errores reportaron hoy
- qué documentación escribieron tus equipos
- o cuáles son las reglas específicas de tu negocio
Asi que si queremos integrar IA dentro de aplicaciones reales, eventualmente necesitamos que el modelo pueda trabajar con información que existe fuera de su entrenamiento: nuestros datos, nuestro contexto y nuestras reglas de negocio.
El primer enfoque que solemos intentar
Cuando aparece este problema, la primera idea normalmente es bastante directa: “Bueno, si el modelo no conoce mi información, entonces se la paso yo”.
Y en esencia, eso es correcto. Los modelos de lenguaje trabajan con el contexto que reciben en el prompt. Se decanta así que, si queremos que respondan usando información de nuestro sistema, necesitamos incluir esa información de alguna manera.
El tema está en que rápidamente aparece otra pregunta: ¿cuánta información le mandamos?
Porque una cosa es pasarle un texto corto, una descripción puntual o algunos datos específicos, pero otra muy distinta es intentar meter documentación completa, historiales, contratos, manuales internos o cientos de páginas de información dentro de cada request.
Por ejemplo, imaginemos que le pedimos algo así: “Usando la siguiente documentación interna [500 páginas de documentación]. Respondé: ¿Cómo cancelo una suscripción?”
Y aunque conceptualmente parezca razonable, en la práctica ese enfoque empieza a romperse bastante rápido.
El problema de mandar todo el contexto
¡Los modelos tienen límites!
Los LLMs trabajan con algo conocido como context window, que básicamente define cuánta información pueden procesar en una interacción. Y aunque los modelos modernos soportan cada vez más tokens, el límite sigue existiendo.
No podemos asumir que el modelo va a poder “leer todo” indefinidamente. Especialmente cuando empezamos a hablar de toda la info que destacabamos antes, que no dejan de ser grandes volúmenes de texto.
Más información no siempre mejora la respuesta
Y este punto probablemente sea el más importante. Cuando uno empieza a trabajar con IA, es bastante natural asumir algo como: “si le doy más contexto, debería responder mejor”.
Pero muchas veces pasa exactamente lo contrario. Si mezclamos información irrelevante con documentos repetidos que tienen texto ambiguo, o incluso datos que no tienen relación con la consulta, el modelo pierde foco. Y como los LLMs no “razonan” de la misma manera que un sistema determinístico tradicional, terminan generando respuestas inconsistentes, imprecisas o directamente inventadas
En IA hay una idea bastante conocida que aplica muchísimo acá: garbage in, garbage out. Es decir, la calidad del contexto impacta directamente en la calidad de la respuesta.
También aparece un problema de ingeniería
Porque además del problema de precisión, está el problema operativo. Mandar enormes cantidades de texto en cada request aumenta costos, incrementa la latencia, consume más tokens y empeora la experiencia general del sistema. Y eso, en aplicaciones reales, termina importando muchísimo más de lo que parece al principio.
Acá es donde aparece RAG
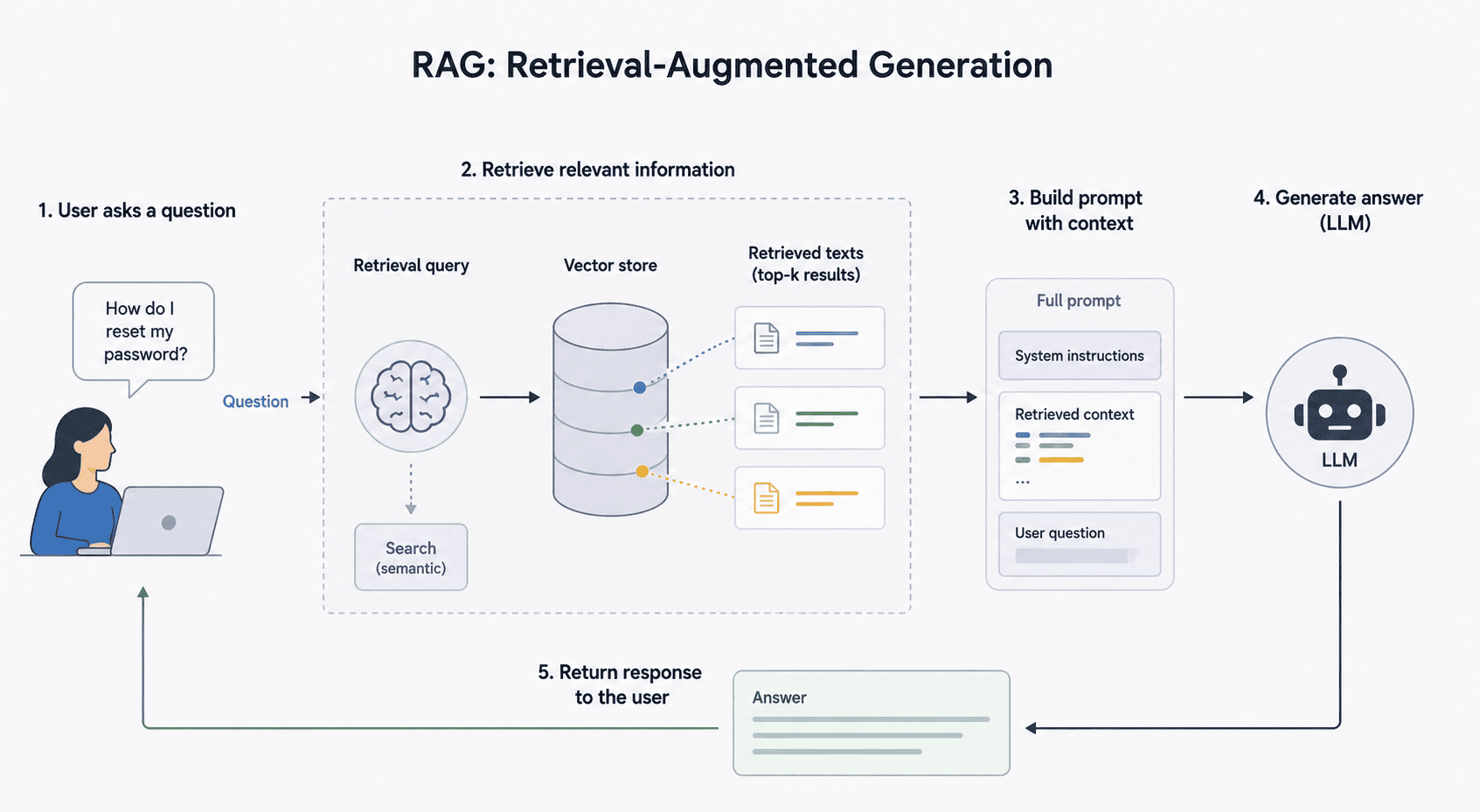
Para resolver este problema, en los últimos años empezó a popularizarse una arquitectura conocida como RAG (Retrieval-Augmented Generation). Y aunque el nombre pueda sonar complejo al principio, la idea detrás es bastante lógica.
En lugar de mandarle enormes cantidades de información al modelo en cada request, el objetivo pasa a ser otro: recuperar únicamente el contexto que realmente importa para la consulta actual.
Ese cambio parece pequeño, pero conceptualmente es enorme. Ahora el problema deja de ser “cómo meter toda la información posible dentro del prompt” y pasa a ser “cómo encontrar la información correcta en el momento correcto”. Ese es, probablemente, el verdadero corazón de los sistemas modernos basados en IA.
El modelo no responde solo
Una de las confusiones más comunes cuando empezamos a trabajar con LLMs es pensar que el modelo “sabe” responder por sí mismo.
Pero en aplicaciones reales, muchas veces el valor no está en el conocimiento general del modelo, sino en el contexto que recibe antes de generar la respuesta.
Por ejemplo, imaginemos un sistema de soporte interno. Si un usuario pregunta “¿Cómo soluciono el error de login?” el modelo, por sí solo, probablemente improvise, adivine o responda usando conocimiento genérico
Pero un sistema RAG hace algo distinto antes de llamar al modelo. Primero:
- busca documentación relacionada
- recupera tickets similares
- encuentra información relevante
- y recién después construye el prompt final
Es decir, el modelo ya no responde “a ciegas”. Responde usando contexto recuperado dinámicamente desde nuestros propios datos. Y eso cambia muchísimo la calidad de las respuestas.
Una forma simple de pensarlo
Mentalmente, podemos pensar RAG como una especie de pipeline de recuperación de información.
El flujo suele verse más o menos así:
- el usuario hace una pregunta
- el sistema busca información relacionada
- recupera los fragmentos más relevantes
- construye un contexto dinámico
- recién ahí llama al modelo
Y esto es importante entenderlo: el modelo no está “recordando” información. La información se recupera en tiempo real y se le entrega como contexto antes de generar la respuesta.
Por eso RAG no reemplaza el conocimiento del modelo, lo complementa.
Ahí es donde la IA empieza a integrarse de verdad dentro de aplicaciones reales, y en el ecosistema Java, Spring AI simplifica muchísimo toda esa integración.
El cambio de paradigma más importante
Hasta acá, el problema parece bastante claro: necesitamos encontrar información relevante para agregarla al contexto del modelo.
La pregunta entonces pasa a ser: ¿cómo encontramos esa información?
Acá aparece uno de los cambios más importantes que introduce este tipo de sistemas. Durante años, en backend estuvimos acostumbrados a recuperar información principalmente por igualdad, coincidencias textuales, filtros, relaciones o patrones bastante exactos.
Pero cuando trabajamos con lenguaje natural, eso muchas veces no alcanza, sencillamente porque las personas no hablan siempre igual. Digo, dos usuarios pueden describir exactamente el mismo problema usando palabras completamente distintas. Ahí es donde empieza a cambiar el paradigma.
El límite de la búsqueda tradicional
Imaginemos un sistema de soporte con tickets almacenados en una base de datos. En un enfoque clásico podríamos hacer algo así:
SELECT * FROM tickets WHERE description LIKE '%error login%';A simple vista parece razonable. Ahora, ¿qué pasa si el usuario escribe algo como: “No puedo entrar a mi cuenta”? o “La aplicación no me deja iniciar sesión”
Semánticamente estamos hablando prácticamente del mismo problema, pero desde el punto de vista textual las frases son distintas, las palabras cambian y el LIKE probablemente no encuentre nada útil, sencillamente porque SQL tradicional está pensado para buscar coincidencias, no significado. Y eso, cuando empezamos a trabajar con lenguaje natural, se vuelve una limitación bastante importante.
Acá es donde entran los embeddings
Para resolver este problema aparecen los embeddings, cuya idea general, aunque el término suele sonar complejo al principio, es bastante intuitiva.
Un embedding es, básicamente: una representación matemática del significado de un texto. A ver, cuando generamos un embedding, el texto deja de ser solamente palabras y pasa a convertirse en una representación numérica que captura contexto y significado.
No importa tanto el array de números en sí. Lo importante es lo que permite hacer. Porque una vez que distintos textos están representados matemáticamente, podemos medir qué tan “cerca” están entre sí desde el punto de vista semántico. Y ahí aparece algo muy potente.
Frases como:
- “No puedo iniciar sesión”
- “Tengo problemas para entrar a mi cuenta”
- “El login está fallando”
aunque textualmente sean distintas, pueden terminar muy cerca dentro del espacio vectorial porque expresan una intención parecida, habiltando así algo completamente diferente a la búsqueda tradicional: búsqueda basada en significado. O dicho de otra manera: dejamos de buscar palabras exactas y empezamos a buscar intención.
Probablemente ese sea uno de los cambios más importantes detrás de toda la arquitectura moderna de RAG.
Entonces, ¿cómo funciona RAG realmente?
Hasta ahora hablamos bastante de la idea general: recuperar contexto, buscar por significado y darle información relevante al modelo.
Pero cuando bajamos eso a ingeniería real, RAG termina funcionando más como un pipeline de procesamiento que como una simple llamada a un LLM.
Entender eso es importante, porque en la práctica, gran parte del trabajo no ocurre durante la generación de la respuesta, sino antes.
A nivel general, el flujo suele dividirse en dos grandes etapas:
- una etapa de preparación de información
- y otra de recuperación en tiempo real
Fase 1: preparación e ingestión de información
Esta etapa ocurre antes de que el usuario haga preguntas y su objetivo es transformar información “normal” en algo que el sistema pueda recuperar semánticamente más adelante.
Lectura de documentos
Primero necesitamos obtener información desde alguna fuente. Bien podrían ser PDFs, documentación técnica, tickets de soporte, archivos Word, JSON, bases de conocimiento, páginas internas o incluso datos de una base relacional.
En Spring AI, esta etapa suele resolverse usando distintos DocumentReader, que abstraen gran parte del trabajo de lectura y parsing. Y aunque parezca una parte menor, en sistemas reales esto ya empieza a ser importante, porque el problema deja de ser solamente “hablar con un modelo” y pasa a ser otro: cómo conectamos nuestros datos reales con la IA.
Chunking: dividir sin romper significado
Una vez que tenemos los documentos, aparece otro problema. No podemos guardar manuales enteros o cientos de páginas como un único bloque gigante de texto. Y tampoco tendría sentido enviarlos completos en cada consulta.
Entonces aparece una técnica fundamental en cualquier sistema RAG: el chunking.
La idea es dividir la información en fragmentos más pequeños — chunks — que después puedan recuperarse individualmente. Ahí el desafío no es solamente cortar texto, es conservar contexto y significado. Porque si partimos una idea en lugares incorrectos vamos a perder coherencia, empeorar la recuperación semántica y el modelo va a terminar recibiendo contexto incompleto o confuso
Entonces, aunque desde afuera parezca un detalle menor, la estrategia de chunking suele impactar muchísimo en la calidad final de las respuestas.
Embeddings: transformar significado en representación matemática
Una vez divididos los documentos en chunks, el sistema necesita una forma de poder encontrarlos más adelante por significado y no solamente por coincidencia textual. Y ahí es donde aparecen nuevamente los embeddings.
En esta etapa, cada fragmento de texto pasa por un modelo especializado que transforma ese contenido en una representación vectorial.
Por ejemplo:
“Error al iniciar sesión”
↓
[0.12, -0.44, 0.91, …]Pero nuevamente, el valor no está en el array de números en sí. Lo importante es que ahora cada fragmento del sistema tiene una representación matemática de su significado.
Eso posibilita algo fundamental para RAG: poder recuperar contexto semánticamente relacionado más adelante.
Es decir, cuando el usuario haga una consulta, el sistema va a poder encontrar fragmentos “parecidos en significado”, aunque no utilicen exactamente las mismas palabras.
Y esto también ayuda a entender otra idea importante: el modelo que genera embeddings no es el mismo que genera respuestas conversacionales. Cumplen roles completamente distintos.
- el modelo conversacional redacta respuestas
- el modelo de embeddings organiza significado matemáticamente
Uno genera lenguaje, el otro permite encontrar contexto relevante.
Vector Store: persistencia para el contexto semántico
Finalmente, esos embeddings se almacenan en una base especializada conocida como Vector Store.
Probablemente, para un backend developer, esta sea una de las mejores formas de pensarlo: el Vector Store funciona como una capa de persistencia para el conocimiento semántico del sistema.
Porque ahí es donde quedan almacenadas las representaciones vectoriales que después van a utilizarse durante la recuperación de contexto. Y aunque todo esto suene muy ligado al mundo IA, en el fondo seguimos hablando de problemas bastante conocidos, como almacenamiento, indexación, recuperación eficiente, performance, latencia o relevancia.
Lo que cambia no es la existencia del problema, sino la estrategia de búsqueda. En una base tradicional solemos recuperar información por igualdad o coincidencia textual. En una base vectorial, en cambio, buscamos cercanía semántica: qué fragmentos tienen un significado parecido a la intención del usuario.
Y aunque internamente todo esto involucra vectores, distancias y cálculos matemáticos, desde el punto de vista del desarrollador muchas veces puede pensarse simplemente como otra estrategia de recuperación de información.
Algunas opciones comunes dentro del ecosistema Java
Hoy existen varias alternativas para trabajar con búsqueda vectorial.
PostgreSQL + pgvector
Probablemente una de las opciones más interesantes para equipos que ya trabajan con PostgreSQL. Pgvector agrega soporte para embeddings directamente dentro de Postgres, permitiendo combinar consultas tradicionales con búsqueda semántica sin incorporar demasiada infraestructura nueva.
Eso tiene bastante valor en sistemas reales, porque muchas veces no necesitás montar una arquitectura completamente distinta para empezar a experimentar con RAG.
Redis
También aparece bastante en escenarios donde Redis ya forma parte de la infraestructura existente.
Pinecone o Weaviate
Son soluciones más especializadas, pensadas específicamente para workloads vectoriales y búsqueda semántica.
Y aunque las bases vectoriales son un tema enorme por sí solo, para esta primera aproximación lo importante no es entender toda su implementación interna, sino la idea general: necesitamos una forma eficiente de recuperar información por significado y no solamente por coincidencia textual.
Fase 2: recuperación de contexto
Una vez que toda la información ya fue procesada, dividida, vectorizada e indexada, recién ahí empieza la segunda gran parte del pipeline: la recuperación en tiempo real, o sea, donde realmente ocurre el flujo RAG.
Porque hasta este momento el sistema solamente “preparó conocimiento”, pero todavía no respondió nada. La recuperación empieza recién cuando un usuario hace una pregunta real. Por ejemplo: “No puedo entrar a mi cuenta”
A simple vista parece un texto corto y bastante ambiguo, pero internamente empiezan a pasar varias cosas.
El sistema primero intenta entender la intención
Lo primero que ocurre es que la consulta del usuario también se transforma en un embedding. Es decir, la pregunta deja de ser solamente texto y pasa a convertirse en una representación matemática de significado. Y esto es importante porque el sistema ya no intenta buscar coincidencias exactas.
Lo que busca es otra cosa: contexto semánticamente parecido.
Entonces, aunque el usuario escriba:
- “No puedo iniciar sesión”
- “La app no me deja entrar”
- “Tengo problemas para acceder”
el sistema igualmente puede recuperar información relacionada al mismo problema. Ese es el verdadero valor de la búsqueda semántica.
Recuperar contexto relevante
Una vez generado el embedding de la consulta, el sistema ejecuta una búsqueda sobre el Vector Store.
Pero en lugar de recuperar filas exactas o coincidencias textuales, busca los fragmentos cuyo significado sea más cercano a la intención del usuario.
Por ejemplo, podría recuperar:
- tickets similares
- documentación relacionada
- soluciones previas
- errores conocidos
- artículos internos
- o fragmentos específicos de una base de conocimiento
Y esto cambia muchísimo la forma de pensar la recuperación de información. Porque el objetivo ya no es solamente encontrar “datos”, sino encontrar el mejor contexto posible para ayudar al modelo a responder correctamente.
Construcción dinámica del prompt
Una vez recuperados los fragmentos relevantes, el sistema construye dinámicamente el prompt final que se le enviará al LLM.
Este punto es clave, porque el modelo ya no responde únicamente usando lo que aprendió durante su entrenamiento, ahora también recibe:
- contexto actualizado
- información privada
- datos específicos del negocio
- documentación interna
- o conocimiento que nunca existió durante su entrenamiento
Conceptualmente, el prompt termina siendo algo parecido a esto: “Utilizando la siguiente información recuperada del sistema, respondé la consulta del usuario…”
Y recién ahí ocurre la llamada al modelo.
El verdadero motor del sistema no es el LLM
Este probablemente sea uno de los cambios conceptuales más importantes de toda la arquitectura RAG.
Muchas veces pensamos que la calidad del sistema depende principalmente del modelo, pero en la práctica, gran parte de la precisión termina dependiendo de otras cosas:
- la calidad del chunking
- los embeddings
- la estrategia de recuperación
- la relevancia del contexto
- y la búsqueda semántica
El modelo, en gran medida, lo que hace es redactar una respuesta utilizando la información encontrada, y eso cambia muchísimo la forma de pensar aplicaciones basadas en IA.
Porque el sistema deja de depender únicamente de lo que el modelo “sabe” y empieza a apoyarse también en información recuperada dinámicamente desde nuestros propios datos.
Cómo simplifica esto Spring AI
Si implementáramos manualmente todo este pipeline:
- generación de embeddings
- búsqueda vectorial
- recuperación de documentos
- construcción dinámica del prompt
- integración con el modelo
la cantidad de código de infraestructura crecería bastante rápido. Y ahí vuelve a aparecer una de las ideas más fuertes del ecosistema Spring: la abstracción.
Spring AI encapsula gran parte de este flujo usando componentes preparados para trabajar con pipelines RAG.
Por ejemplo, usando QuestionAnswerAdvisor:
@Service
public class SupportService {
private final ChatClient chatClient;
public SupportService(ChatClient.Builder builder,
VectorStore vectorStore) {
this.chatClient = builder
.defaultAdvisors(
new QuestionAnswerAdvisor(vectorStore)
)
.build();
}
public String solveIssue(String userProblem) {
return chatClient.prompt()
.user(userProblem)
.call()
.content();
}
}Lo interesante de este ejemplo no es solamente el código en sí, sino todo lo que abstrae detrás. El desarrollador ya no tiene que preocuparse manualmente por generar embeddings, construir queries vectoriales, recuperar documentos, concatenar contexto, ni mucho menos generar prompts gigantes
El advisor se encarga automáticamente del pipeline de recuperación y augmentación antes de llamar al modelo.
Probablemente ahí esté uno de los mayores aportes de Spring AI: permitir integrar capacidades de IA dentro de aplicaciones Java sin tener que implementar toda la infraestructura del pipeline desde cero.
RAG también tiene problemas reales
Hasta acá, RAG probablemente suene bastante prometedor, y en muchos casos realmente lo es. Pero también es importante entender algo: cuando empezamos a integrar IA dentro de aplicaciones reales, dejamos bastante rápido el terreno de las demos y empezamos a entrar en problemas de ingeniería bastante concretos.
Porque RAG no elimina la complejidad, en muchos casos, simplemente la mueve de lugar.
Recuperar contexto también tiene límites
Aunque el objetivo sea darle información relevante al modelo, seguimos dependiendo de algo que no desaparece: los límites de contexto del LLM.
Ya que no podemos recuperar y enviar cantidades infinitas de información, entonces ¿qué contexto vale realmente la pena incluir?
Y esa decisión termina impactando muchísimo en la precisión, los costos, la latencia y la calidad de respuesta. Porque en sistemas RAG, más contexto no siempre significa más precisión. Muchas veces significa más ruido.
La calidad de la recuperación importa muchísimo
En sistemas RAG, gran parte de la calidad final depende de la recuperación de contexto.
Si la búsqueda semántica trae chunks irrelevantes, documentos ambiguos, información mezclada o contexto incorrecto, el modelo igualmente va a intentar construir una respuesta con eso. Con lo cual, van a aparecer respuestas inconsistentes, mezcla de conceptos, información inventada o las famosas hallucinations.
Por eso, en la práctica, un sistema RAG no se trata solamente de “conectar una IA”. También implica pensar cómo dividimos la información, cómo indexamos embeddings, qué recuperamos, cuánto contexto agregamos y qué tan relevante tiene que ser un resultado antes de usarlo
También aparece un costo operativo
Otro punto importante es que RAG agrega etapas adicionales al flujo de procesamiento.
Como decíamos, ahora el sistema necesita:
- generar embeddings
- ejecutar búsquedas vectoriales
- recuperar contexto
- construir prompts dinámicamente
- y recién después llamar al modelo
Todo eso suma latencia, consumo de recursos, complejidad operativa y costos. Cuando pensamos en aplicaciones reales con tráfico, usuarios y SLAs, esos detalles empiezan a importar bastante más de lo que parece en una demo local.
Entonces… ¿qué aporta realmente RAG?
Después de todo esto, probablemente la parte más interesante de RAG no sea la matemática ni los embeddings. El verdadero aporte es otro.
RAG cambia la forma en la que integramos modelos de lenguaje dentro de sistemas reales, porque el modelo deja de depender únicamente de lo que aprendió durante el entrenamiento y empieza a trabajar también con información recuperada dinámicamente desde nuestros propios sistemas.
Ese cambio es enorme. Significa que la IA ya no responde solamente “por lo que sabe”. Ahora también puede responder usando nuestra inmformación del negocio.
Y probablemente ahí esté una de las razones por las que RAG se volvió tan importante dentro del desarrollo moderno de aplicaciones con IA. No porque haga al modelo más inteligente. Sino porque lo vuelve mucho más útil dentro de sistemas reales.



